 Interview with founder and CTO Chetan Venktatesh
Interview with founder and CTO Chetan Venktatesh
Date: 20 August 2014
Atlantis Crunchbase Profile
In succession to the interview with CEO Bernard Harguindeguy I had the pleasure to speak with the CTO of Atlantis, Chetan Venkatesh.
As the founder of Atlantis, he provided great background to Atlantis. Enjoy the interview!
Willem ter Harmsel: Can you run me through the genesis of Atlantis Computing?
Chetan Venkatesh:  I can! I’ve been an entrepreneur most of my life and started Atlantis in 2006. I spent a lot of time in the datacenter, storage and Infrastructure space. I was keen to to explore the software that was on the server side to do something intelligent with storage.
I can! I’ve been an entrepreneur most of my life and started Atlantis in 2006. I spent a lot of time in the datacenter, storage and Infrastructure space. I was keen to to explore the software that was on the server side to do something intelligent with storage.
We had Moore’s law deliver twice the horsepower at half the cost. I was inspired to create a storage model that took advantage of these increasing CPU cycles and RAM on the server side.
I wanted to bring data services like de-duplication and compression, that require a lot of CPU power, right next to the application.
(Smiling) It turns out that this is much harder idea to implement in practice than said. It took us almost 3 years to complete the first version of the product and we launched in 2009.
We ended up with an interesting dilemma which is; we created a solution to a problem that nobody really had. Added to that, many customers felt very uncomfortable that we were using RAM as a storage tier and associated lots of risk with that.
I was lucky to be speaking to a lot of companies that were experimenting with VDI, and in need for a lot of I/O that we could deliver. Another reason VDI ended up to being a natural place for us to start was that the risk of using non-persistent RAM for often times non-persistent virtual desktops was perceived to be low.
Read my interview with former CEO of Atlantis, Bernard Harguindeguy
Fast forward 6 years, we’re now at about 460+ customers and more than 500.000 licenses in production. We actually deliver more than 14 PB of storage today, which is quite a substantial amount.
About 2 years back, we found that customers were using our product for production databases. One client was running an Exchange database for 5.000 users on our product. We realised our customers were slowly taking the mental leap of using RAM as storage.
The idea behind our latest product Atlantis USX is to build a fast and intelligent software layer, that creates the storage the application requires. We pool and abstract all the resources already present in the datacenter. On top of that abstraction layer now create the virtual volumes that could completely represent the type of storage the application needs.
Our goal was to offer the customer intelligent storage policies, by offering 4 storage models. You can essentially tell the USX layer which applications should land on the local, NAS and SAN layer all from a policy level.
Essentially we offer a virtual storage layer that abstracts the storage beneath it, in the same way that VMware vSphere completely abstracts and virtualizes the server hardware beneath it.
It has been a long journey to that way of thinking, we notice our clients are getting really excited about the possibilities our new product offers.
WTH: Thanks for that background! The notion of using RAM was quite a tricky one in my mind, have you encountered problems with the initial ILIO product?
CV: We realised that using RAM was a sensitive issue, that is why we first focused on the non-persistent VDI use case. We slowly moved to persistent desktops as soon as our confidence grew.
By 2011 we had a fully baked persistence product. Actually 65%-70% of our licenses are persistence based. That is both because technology has matured, but also because it is hard for customers to run stateless, non-persistent desktops with the number of applications they use.
WTH: On a technical level, say I have an application running on a host and it sends a write towards the memory. How does the write get replicated and when does it get send to the local storage, SAN or NAS?
CV: We build an in-memory de-duplication engine, so everything we do for replication is related to de-duplication. We exploit the de-duplication first to minimize the amount of data that needs to be replicated. There are at least 3 copies that are placed within a cluster, in addition it will take metadata belonging to the de-duplication cases and put that in as many places as possible.
Say there is an 8 node cluster, when you have 3 nodes available you are fully protected and have complete information about everything available. Additionally, the remaining 5 nodes will be used to place meta data copies so that you get better redundancy and parallel performance.
A lot of the data placement is defined by the type of storage volume you want to create. Depending on the storage model you have chosen, the software is able to take physical storage assets and create a storage pool out of that. It does the same with RAM.
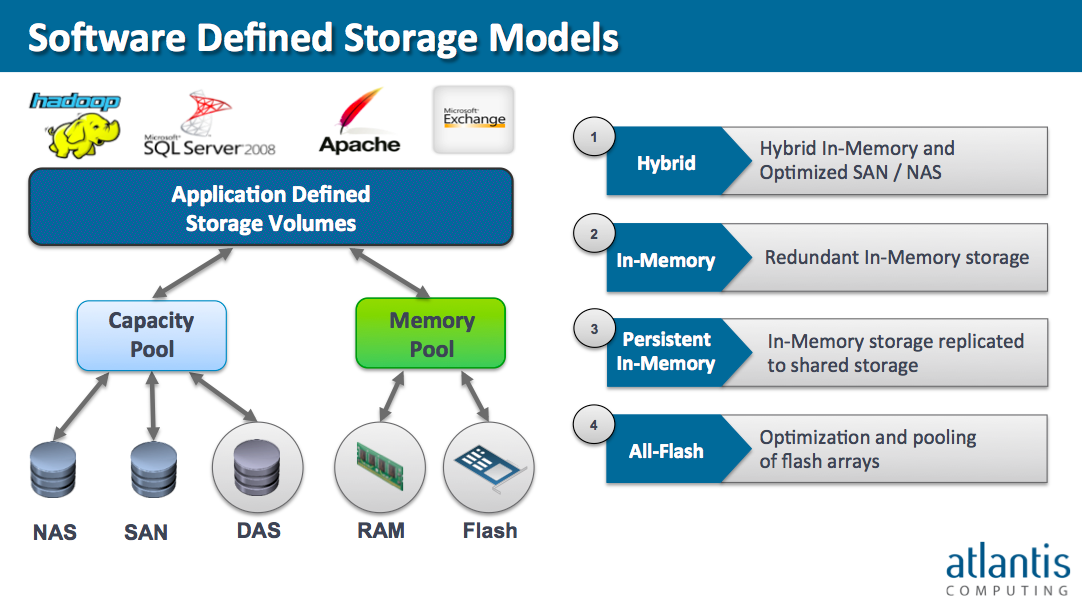
WTH: How does the write sequence differ between the Hybrid and All-flash storage model?
CV: The situation depends on the storage model that the customer selected. For the Hybrid model, the acknowledgements is not done based on whether the write got sent to the physical layer, it relies on a defined minimum number of 3 nodes to acknowledge they received the information. As soon as the minimum number of nodes have acknowledged, it is done, so that USX does not have to wait for the underlying storage.
That way you can abstract the storage underneath from a performance standpoint and make use of the memory performance, while maintain good data protection.
If we’re using the all-flash model, then essentially it waits for the flash tier to acknowledge before USX can acknowledge back to the application.
So based on the type of storage model you use, you have a very fine model to affect write acknowledgement.
WTH: Using the all-flash model, USX will wait for the underlying all-flash array to acknowledge, instead of waiting for peers left and right of the node?
CV: Yes. In all-flash you actually have 2 models. The first is when you have an all-flash array in the back like a fast Pure Storage or Violin Memory array. In that case it is very simple, we’re going to de-duplicate, compress the data and dump it on the all-flash array and acknowledge it as soon as the flash tier has accepted it. This is actually very fast, the latencies are very low on this.
In the second all-flash model, you have very fast locally installed PCIE connected flash or Diablo Technologies MCS. In that case it reverses back to the cluster model where as long as a number of minimum number of nodes have acknowledged they have received the I/O It will acknowledge the I/O back.
Read my interview with the CEO of Diablo Technologies, Riccardo Badalone
WTH: Ok, so depending on the precise storage configuration there are various write-acknowledgement policies available. That could get complicated for an administrator or a not-so-technical reporter like myself.
CV: The main take-away for customers is that they don’t need to worry about the details, the policies adapt themselves to the situation. Your data is always protected.
WTH: I could imagine customers want to speak with Atlantis consultants before they decide on which physical storage configuration to use and which USX storage model to run.
CV: The rule of thumb between a mode is really that if you need a mix between performance and capacity then build a hybrid. If you don’t care about capacity, then use in-memory mode. If you want to use fast mode of persistent storage, then use the all-flash mode. We have written down a lot around these models that customers can use.
WTH: How did you pick all the right people to support the comprehensive product you now have?
CV: We have a lot of employees that come from all-flash start-ups that weren’t going anywhere. Then we recruited many skilled employees from traditional storage companies that were bored and were looking for a challenge. We have an engineering team that is composed of some of the smartest guys in storage, with an average of 14 years of experience. At least a third of our employees are in engineering.
WTH: Compared to companies like PernixData or Infinio, that for now focus purely focus on acceleration, you guys have an enormous set of features. What competitors do you have? The only one I can think of is Maxta.
Read my interview with Yoram Novick, CEO of Maxta
CV: Yes. Well Maxta I do not as of yet consider to be a competitor because they are so early, but in terms of features there are similarities. Technologically speaking this a competitor, but we are not competing with them yet at customers.
WTH: I already asked Bernard after his thoughts on the Atlantis culture. What typifies an Atlantis employee according to you?
CV: This is my third company and along the way you learn from your mistakes. I want Atlantis to be one of the places people will always remember as one of the highlights of their careers. Rather then them thinking about the amounts of money they made, rather I would be proud if Atlantis brought them a great sense of satisfaction and accomplishment.
We really started to focus on a culture that is very much can-do and pragmatic. We look for people that can keep their egos at the door and rally be effective in a team. Second thing is finding people that are really good at solving problems in a collaborative manner.
The third challenge we had Willem is that this is a fast-forward company. We have been doubling the company in terms of revenue and customers over the last 4 years.
Especially in Europe pace is fast, our revenue is more than 50% from there. Europe is actually ahead of the US in terms of the technology adaption. If you take a country like Holland for example, they were doing desktop virtualization 5 or 6 years before anyone else.
So we need people who have an appreciation for how to work in a fast-forward environment and how to be able to look out 6 months ahead. Unless you are thinking 6-12 months, you’re not going to be able to execute ahead of time.
To keep up the succes we look for passionate people that can articulate the vision, take the technology and map it to the challenges a customers have.
WTH: Thanks for sharing your story Chetan and I look forward to staying in touch
Read the interview with fomer CEO of Atlantis Computing Bernard Harguindeguy
Geef een reactie