![]() CloudPhysics, interview with CEO John Blumenthal
CloudPhysics, interview with CEO John Blumenthal
Date: 30 September 2013
CloudPhysics CrunchBase profile
Introduction to CloudPhysics
A company’s IT Infrastructure is crucial to its survival and succes, which is why most companies invest heavily in their IT Infrastructure to reduce risk and increase performance.
Despite these investments, the complex and dynamic nature of IT Infrastructure environments means that most companies do not have a complete picture of their IT infrastructure and the workloads that run on it. There is a risk and performance penalty associated with this.
The risk lies in making changes to your largely unknown environment; like adding resources, adding workloads and changing policies. These can have unpredictable effects that jeopardize the stability of your IT Infrastructure. To mitigate this risk, companies create separate Test & Development infrastructures to test new configurations. However these are costly and time-consuming, plus some real-world scenarios cannot easily be replicated.
The performance penalty arises from the fact that an unknown IT Infrastructure can not use its resources optimally.
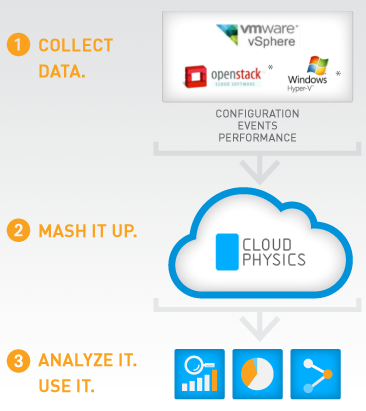
Enter CloudPhysics. They have developed a non-disruptive data collection technique for VMware vSphere environments where data about the IT Infrastructure and the workloads that run on it are collected.
This data is analysed using VMware knowledge databases and anonymized user-data from other CloudPhysics customers.
Based on this analysis, IT administrators are given a set of recommendations with precise execution directions to reduce risk and optimize performance in their IT Infrastructure.
CloudPhysics offers a great number of services that allow IT administrators to dry-run emergency procedures like fail-overs on the real production environment and evaluate the impact of new technology on their production environment.
I interviewed John Blumenthal, CEO of CloudPhysics to get more insight into their product and to hear his views on the market.
Great to meet you John, do you actually get to take a few days off at the end of the year?
 Yes we do have a few days off. It is changing a little bit in Silicon Valley now, some of the biggest companies are actually closed during the two week period around the end of the year. In the start-up scene that is a little bit different, but we do have a few days off. I will work from home a couple of days and people are taking it a little bit easy, but it’s getting all wrapped up for the beginning of next year.
Yes we do have a few days off. It is changing a little bit in Silicon Valley now, some of the biggest companies are actually closed during the two week period around the end of the year. In the start-up scene that is a little bit different, but we do have a few days off. I will work from home a couple of days and people are taking it a little bit easy, but it’s getting all wrapped up for the beginning of next year.
Dozing off completely at the end of the year is not a smart idea I guess?
(Laughs) No, especially if you have venture capital on board and have a burn-rate to deal with.
So how are things going John, just in general?
We are doing great! I am quite amazed by the attention we received. The launch at VMworld in San Francisco went very well and we seem to have a strong appeal to VMware admins and specialists that design and implement IT infrastructure.
CloudPhysics extensively gathers information and suggests changes and optimization strategies, does it implement them as well?
Not yet. We do make recommendations; our goal is to not just find a problem, but also to provide an execution path and a remediation plan in the analytics that we are delivering. We believe that is the next generation of how data is put into use by a VMware admin or designer.
It is not enough just to index and search this data to look for correlations but to actually find causation. There is a known phrase in data science, that correlation is often not causation. In fact they’re often times never related.
We think that a lot of log analytics platforms which effectively allow you to do these forms of searches, fall short of what an administrator needs to find, which is an analytical based answer that provides a direction of what to do.
However we do not take the final step, which is to actually execute the recommendation. That has to do more with the nature of a SAAS service attaching to your network and the concerns people have about a remote system actually executing changes in your environment. So we go as far as the data and the execution plan, but not the actual execution at this time.
Do you imagine developing a perhaps locally installed add-on that does allow for execution in the near future?
We do. We ultimately intend to do that and deal with all the security concerns. So in that sense it will look like a highly informed resource management approach. Among the team members we have people that were responsible for a lot of the resource scheduler at VMware.
Our idea has been to implement greater quality and quantity of the analytics that drive those changes. As the market adopts our solution we will step forward with options for making these final changes, as you pointed out.
So a large portion of your team consists of ex-VMware and ex-Google employees right?
Yes indeed. One of my co-founders Irfan Ahmad was core in the DRS team and the author of storage DRS and Storage IO control and Carl Waldspurger that works with us as an advisor was the actual principal engineer responsible for the original architecture and implementation of DRS. Carl spends quite a bit of time with us on architecture and direction.
Is it true that VMware is looking at CloudPhysics and scratching its head now, thinking they should have come up with this solution?
VMware was and is a great company and many of us have made our careers there, so in many ways it is regarded as the mothership. Many of the things we were working on were not really in scope with the work that was being done at VMware, mainly because this is a SAAS oriented approach to delivering analytics which is unlike the on-premise approach that VMware took.
We have many discussions with VMware we are in the partnership program. We still have a great deal of allegiance and interest in offering more value to VMware customers.
How quickly can CloudPhysics include new technologies like PernixData, Infinio and others and suggest recommendations on these?
Something like PernixData is very interesting layer that your IT infrastructure might contain.
Our goal is to ultimately model, simulate an entire datacentre. Today we have broken it down in smaller discrete simulations, one of which has to do with caching. We have a caching analytics service with a module that allows us to work with any vendor and make tweaks to that model to incorporate effectively how their caching mechanism works.
We sit down with a lot of storage vendors like Fusion IO, Proximal Data and we are very well known with the PernixData guys from our times at VMware.
Sitting with Satyam Vaghani and Frank Denneman would be great to update the information on PernixData so that a user can run a CloudPhysics service before the procurement of Pernix and understand the value proposition and benefit of introducing Pernix before they even purchase. Use real data to do that, avoid a POC and the cost and exercise that comes along with that.
So CloudPhysics customers can dry-run new technology to see how it will impact their actual production environment?
That is one of our main use cases yes. The procurement process is often a very wasteful exercise in today’s IT Infrastructures because your storage vendors do not actually know your environment and conversely you don’t really understand their technology.
The way the dance goes today, is a kind of kabuki theatre with sales and presales. It involves trying to replicate a production system and generate data that may or may not be indicative of what would actually happen in production.
So we looked at this and said, we can build a model of caching technology that has a mathematical model basis to it. We then gather workload traces non-disruptively from a cluster – and that is our secret sauce, being able doing these collections non-disruptively.
Then we can run these traces through our simulator and then literally within 2 to 3 % variance indicate to a user what the benefit would be for one or a group of workloads that are running in a cluster with a cache of a certain size. That benefit is highly accurate and highly quantitative.
You can avoid a lot of danger involved with making wrong purchases this way too.
Being able to simulate exactly what is in production and do that non-disruptively without having to spin up a proof of concept is what we believe is the future of how IT infrastructure will be sold.
Do you consider this to be your biggest use case?
It is the one that is bringing revenue to the company most immediately. We build this as one of our first services about a year ago and it gathered interest of many storage vendors. It is the basis of the companies first revenues.
But expanding upon that are other services that we introduced that are focused less on the procurement accuracy and efficiency and more on Risk and Safety.
For example we have a High Availability simulator, which has an HA health check service attached to that too. This is based on the work that Frank and Duncan have put together in their analysis and writings on High Availability. We have actually encapsulated much of that in our HA simulator and HA health check services.
The nature of the problem we are solving here, is as you provision virtual machines or modify HA policy groups you don’t have visibility into the impact of those changes. Meaning you do know not whether you have reserved enough remote resources in order to succeed in the event of a fail-over.
Our simulators allow you to look at the consequences of a particular change and understand very accurately whether you are actually wasting resources by having too much capacity or not enough in which case you will not have a successful fail-over.
Additionally we have a couple of other services that are focused on understanding particular operational hazards are starting to kick in and take on dramatic interest among the user base that we are involved with.
Is CloudPhysics still limited to VMware, or are Openstack and Microsoft Hyper-V in the picture already?
We are exclusively focused on vSphere customers today. We are in the throes of making a decision what hypervisor to support next, whether it will be either KVM and Openstack or Hyper-V. We should be making that decision in the next month.
The VMware specific experience in your team must be crucial to the non-disruptive collection ‘secret-sauce’. This experience cannot be leveraged in Hyper-V or KVM environments, right?
There is very specific ‘secret sauce’ that we filed patents around that go beyond just the specific nature of our expertise in collections out of VMware environments. The collection techniques have direct application to other hypervisors, independent of the nature of how you would collect.
So there is an hyper-visor independent part of the ‘secret sauce’, but still you will require to hire experienced Hyper-V or KVM engineers ?
Absolutely, expertise on those interfaces is a specialized skillset and we absolutely invest in those.
More generally now, the whole vague term of ‘Big Data’ frustrates me a bit. What is your view on what people call ‘Big Data’ today?
I share your frustration and I think it is an overused, hyped term. What is big today may be small tomorrow.
Our vision around it and the labels we’ve used is really derived from Google and other large-scale infrastructures. If you look at how Linkedin or Google run their Infrastructures, what you quickly realize is that they have heavy data collections that is put onto an operational platform for running analytics, to actually then operate the infrastructure.
The platform that collects all that data internal to these large backend system is in fact the same thing we are doing for VMware environments.
What we are doing is mimicking the type of analytical approach that is being used to run the world’s largest infrastructures in the world and bringing that approach to VMware users.
In that sense, large amounts of data are absolutely required for analysing configurations, performance. Using real data science techniques for understanding optimizations as well as risks.
Unfortunately that falls under the marketing term of Big Data, which is overused. We believe it is essential to taking IT infrastructure to the new level. We are giving people that are running VMware a chance to run at the same type of utilization as the people at Facebook, Linkedin and Google.
Are the data-collection and analysis techniques that you are applying to IT Infrastructure today, applicable to completely different types of datasets?
Actually this is one area where I am going to have to disagree Willem. The lesson we are learning from operating in the Big Data space, is that the platform that you construct to manage and process the data and be able to model it and turn back causation, you actually have to tie that very specifically to the very data that you are collecting.
We believe that the first rule of business in IT Operations management and analytics is ‘Know thy data’.
If you look at the history of many of the system management platforms, the underlying algorithms that were developed that drive a lot of these things were never really constructed with the intention of running IT Operations.
Examples of this are Netuitive, Integrien that was acquired by VMware and some of the things IBM has been running as a part of Tivoli. The algorithms driving the processing of the data were never constructed from the ground up with domain expertise around what the data contains and how the data is actually modelled.
One of the fundamental premises at CloudPhysics is that our backend is very specific to the processing at scale of systems management data, where the core four resources of Network, CPU, Memory and Storage are related in a way that virtualization domain expertise can only do.
That’s what drives the data structures, how we manage it on the backend and how we process it algorithmically. We believe this approach is just fundamentally different than the way other systems management approaches have been assembled using fundamental algorithms that we never really designed for systems management.
Therein lies the difference in the quality of the type of analytics that we can generate.
That approach makes a lot of sense. So the opposite hypothesis I proposed is something that some of the competitors are doing?
Yes, you’d see elements of exactly what you’re saying with Splunk for example. Their platform is restricted to unstructured log data that can be indexed and then searched. Splunk’s ambition is to do this not just across IT but also the internet of things where any log is subject to their type of indexing and searching.
I believe that is valid, I just don’t believe it adds to the ability to find causation in systems management data.
Allright! See you helped to lift the veil on Big Data, the smoke is slowly clearing! Thanks for that!
(Laughs) I’m glad!
Back to the team you have now, how big is CloudPhysics now?
We’re 25 now and growing, most of the team is engineering. We have recently attracted a first class VP of Marketing, Melinda Wilken, who also spend time at VMware and was most recently at Couchbase. Melinda is designing much of marketing and messaging right now.
So we’re filling out the business side of the company as we speak. We’re doing this in concert with the onboarding of our first users.
Diane Greene and Mendel Rosenblum are investors in your company, how involved are they?
Well Mendel and Diane are some of the best possible investors in virtualization and enterprise software. They are very actively involved across a whole suite of companies. I am very lucky to get access to Diane in the course of looking at the operations and strategy of the company. She has been very gracious with her time, we get access to her as much as she can afford it. It is a great relationship. We’ve all spend time at VMware under her tenure and we’re not only benefiting from that experience but also from her ongoing interest in the company.
How involved are Kleiner Perkins and the Mayfield Fund?
They are very involved. Our latest round was led by Kleiner Perkins’ Mike Abbott, who was the VP of Engineering at Twitter. At the strategic level, Mike Abbott and Robin Vasan of the Mayfield Fund provide great guidance and strategy, and they help to draw talent to the team. The latter is especially essential in a competitive labor market like silicon valley’s. They really help us there.
VMware has various departments like NSX that are largely separate from the rest of the organization. Could you have imagined yourself run CloudPhysics from within VMware?
At the time that I was at VMware, no. I was there until the end of 2011 and until that time the entire focus has been on on-premise, proprietary licensable software.
That is very different from what we’re doing which is much more SAAS oriented and analytically driven as opposed to feature driven which is how the Hypervisor on which I was working was developed.
At the time VMware did not have the genetic make-up to build a SAAS oriented approach to the world. I think that is changing at VMware now. What we’re doing now was not possible inside VMware at the time.
It is really critical to find investors that understand the domain and the stakes deeply, otherwise you end up in a bad situation of misalignment.
Looking back at your career at Symantec and VMware and now CloudPhysics, what has been central to your drive?
You have to fall in love with a problem. You have to find a problem that keeps you up at night and that drives you almost obsessively.
You combine that with a certain level of grit and the desire to see something through. For me, it’s really that primitive.
I think in start-ups, especially taking on venture money, you really need to find something that you’re passionate and obsessed about solving. I think that if you do find that, people in your domain will be attracted to it and will jump on board trying to solve something that is a harder problem and that is compelling.
Compared to my time at VMware, the experience at CloudPhysics is highly intensified now. We’re a small company, you have employees that need to share in the drive to be successful. It is not for the faint of heart and it is extremely exciting.
It is a tremendous experience. Seeing your idea in reality is great, I wouldn’t trade it for anything.
We will follow up on CloudPhysics, stay tuned for more news.
Background and links
CloudPhysics website
Great introductory article by Frank Denneman
Great article by Duncan Epping
CloudPhyics Labtest by TheRegister’s Aaron Milne
Crunchbase profile CloudPhysics
Geef een reactie